Kurzer Rückblick: Einheit 2
Systeme & Komplexität
Was ein System ist, Weaver's drei Problemklassen, Cilliers' sechs Merkmale komplexer Systeme.
Modelle & ABM
Was ein Modell ist, der Modellierungszyklus, vier Modellierungsansätze, ABM-Definition, Emergenz.
ODD & Tooling
Einführung ins ODD-Protokoll (7 Elemente), Setup von Python, VS Code, Git, GitHub.
Tooling-Check
Warum systematisch beschreiben?
Die Systemanalyse hat das Ziel, ein System zu verstehen. Verstehen heißt nicht nur Fakten über Komponenten kennen, sondern Hypothesen über das Systemverhalten aufstellen und testen zu können.
Mobus & Kalton (2015), Kap. 12
Vom Modellzweck zur Beschreibung
Zweck als Filter
Ein Modell ohne klaren Zweck ist nutzlos. Der Zweck bestimmt, was ins Modell gehört und was nicht.
- Welches System modellieren wir?
- Welche Frage wollen wir beantworten?
- Welche Ergebnisse erwarten wir?
Skizziert den "Schlüsselgraphen" eurer Ergebnisse. Was ist auf der x-Achse? Was auf der y-Achse?
Von der Black Box zum Modell
Inputs →
???
System of Interest
→ Outputs
ODD im Überblick
Three Blocks, Seven Elements
Overview
- Purpose and Patterns
- Entities, State Variables, and Scales
- Process Overview and Scheduling
Design Concepts
- Design Concepts
11 Sub-Konzepte als Checkliste
Details
- Initialization
- Input Data
- Submodels
ODD ist gleichzeitig ein Dokumentationsformat und ein Denk- und Designwerkzeug. Die hierarchische Struktur zwingt uns, zuerst das Wesentliche zu klären, bevor wir in Details gehen.
Grimm et al. (2006, 2010) · Railsback & Grimm (2019), Kap. 3
Element 1: Purpose and Patterns
Purpose
Eine klare, spezifische Aussage über die Frage oder das Problem, das das Modell adressiert.
- Welches System modellieren wir?
- Was wollen wir darüber lernen?
- Tipp: Benutzt das Wort "Specifically, …" früh in der Beschreibung
Wenn Designentscheidungen schwerfallen: zurück zum Purpose. Der Purpose ist der Kompass.
Patterns
Welche beobachtbaren Muster soll das Modell reproduzieren? Das sind die Kriterien, wann das Modell gut genug ist.
- Generische Modelle: allgemeine Muster (Zyklen, Gleichgewichte, räumliche Strukturen)
- Spezifische Modelle: konkrete Felddaten, Messwerte, Beobachtungen
Auch wichtig: welche Muster das Modell nicht reproduziert, kann Hinweise auf Fehlendes geben.
Railsback & Grimm (2019), Kap. 3
Element 2: Entities, State Variables, and Scales
Entities
Die Dinge im Modell: Agenten, Umgebungszellen (Patches), die globale Umgebung.
State Variables
Beschreiben den Zustand jeder Entity. Was muss das Modell über jede Entity wissen?
| Entity | State Variables |
|---|---|
| Wolf | Position, Energie, Alter |
| Schaf | Position, Energie |
| Gras-Patch | Zustand (gewachsen/abgefressen), Timer |
Scales
Railsback & Grimm (2019), Kap. 3 · Abb. Fabian Veider
Element 3: Process Overview and Scheduling
Prozesse
Was tun die Entities? Jeder Prozess ist an eine Entity gebunden: Bewegen, Fressen, Verkaufen, Sterben…
Ausnahme: Observer-Prozesse sammeln Daten über das Modell (Grafiken, Statistiken, Output-Dateien).
Aus Simulationen kennt ihr das als Zeitschritte oder Ticks: in jedem Tick führen die Agenten ihre Prozesse aus.
Scheduling
Die Reihenfolge, in der Prozesse ausgeführt werden, beeinflusst das Ergebnis.
Diese Wahl ist eine Designentscheidung, die dokumentiert und begründet werden muss.
Railsback & Grimm (2019), Kap. 3
Element 4: Design Concepts (Teil 1)
Agentenverhalten und Modellprinzipien
| Concept | Leitfrage |
|---|---|
| Basic Principles | Welche Theorien oder Hypothesen liegen dem Modell zugrunde? |
| Emergence | Welche Ergebnisse entstehen aus dem Verhalten der Agenten, welche sind durch Regeln erzwungen? |
| Adaptation | Welche Entscheidungen treffen die Agenten? Wie reagieren sie auf Veränderungen? |
| Objectives | Was optimieren die Agenten? (Fitness, Nutzen, Profit…) |
| Learning | Ändern Agenten ihre Entscheidungsregeln über die Zeit? |
| Prediction | Wie antizipieren Agenten zukünftige Zustände? |
Railsback & Grimm (2019), Kap. 3, Tab. 3.1
Element 4: Design Concepts (Teil 2)
Wahrnehmung, Interaktion und technische Entscheidungen
| Concept | Leitfrage |
|---|---|
| Sensing | Was können Agenten über ihre Umgebung und andere Agenten wahrnehmen? Über welche Distanz? |
| Interaction | Wie beeinflussen sich Agenten gegenseitig? Direkt oder indirekt (z.B. über Ressourcen)? |
| Stochasticity | Wo und warum wird Zufall verwendet? (Initialisierung, Verhaltensvariabilität, nicht-modellierte Ursachen) |
| Collectives | Gibt es Gruppen von Agenten, die als Einheit handeln? |
| Observation | Welche Outputs brauchen wir, um das Modell gegen unsere Patterns zu testen? |
Railsback & Grimm (2019), Kap. 3, Tab. 3.1
Fokus: Emergence als Design Concept
Drei Kriterien
Ein Modellergebnis ist emergent, wenn:
- Es nicht einfach die Summe der Eigenschaften der Individuen ist
- Es ein anderer Typ von Ergebnis ist als die Eigenschaften einzelner Agenten
- Es nicht leicht vorhersagbar ist, nur aus den Agenteneigenschaften
Das Gegenteil: imposed (erzwungen) bedeutet, das Ergebnis folgt direkt und vorhersagbar aus den Modellregeln.
Das richtige Maß
Emergence bewegt sich auf einem Spektrum von imposed bis emergent.
Mehr Emergence ist nicht immer besser:
- Zu imposed: Das Modell ist langweilig, die Ergebnisse sind trivial vorhersagbar.
- Zu emergent: Zu viele komplexe Interaktionen machen das Modell selbst zur Black Box, die man nicht mehr versteht.
Das beste Maß ist oft intermediär: einfache Agentenregeln, die nicht-triviale Systemmuster erzeugen.
Railsback & Grimm (2019), Kap. 8
Elemente 5-7: Initialization, Input Data, Submodels
5. Initialization
Wie starten wir die Simulation? Anzahl der Agenten, Anfangswerte aller State Variables, Umgebungskonfiguration. Für Reproduzierbarkeit: auch den Random Seed angeben, damit stochastische Simulationen exakt wiederholbar sind.
6. Input Data
Externe Daten, die sich während der Simulation ändern und eingelesen werden (z.B. Temperaturverläufe, Marktpreise). Nicht gemeint: Parameterwerte oder Initialisierungsdaten.
7. Submodels
Die detaillierte Spezifikation jedes Prozesses: Gleichungen, logische Regeln, Algorithmen. Alle Parameter mit Bedeutung, Einheiten, Standardwerten und Wertebereichen. Hier wird das Modell vollständig reproduzierbar.
Zusammen bilden diese drei Elemente die Implementierungsebene: aus dem Überblick (Elemente 1-3) und den Designentscheidungen (Element 4) wird ein vollständig spezifiziertes Modell.
Railsback & Grimm (2019), Kap. 3
ODD in der Praxis
Schmetterlinge nutzen die "Hilltopping"-Strategie: sie fliegen bergauf, um sich auf Hügelkuppen zu treffen und zu paaren. Können durch dieses einfache Verhalten "virtuelle Korridore" entstehen, also Pfade, die viele Schmetterlinge nutzen, obwohl dort kein besonderer Lebensraum ist?
Ein extrem einfaches Modell, das drei wissenschaftliche Publikationen ermöglichte.
Pe'er et al. (2005) · Railsback & Grimm (2019), Kap. 3.4
Butterfly ODD: Overview
Elemente 1-3
1. Purpose and Patterns
Unter welchen Bedingungen führen Hilltopping-Verhalten und Landschaftstopographie zur Entstehung von virtuellen Korridoren?
Patterns: Schmetterlinge erreichen Hügelkuppen; Bewegung hat eine starke stochastische Komponente.
2. Entities, State Variables, Scales
Zwei Typen: Schmetterlinge (nur Position) und Patches (nur Höhe). 150 × 150 Gitter, ~25 m pro Patch, 1000 Zeitschritte.
3. Process Overview and Scheduling
Ein Prozess: Bewegung. Jeder Schmetterling bewegt sich einmal pro Zeitschritt.
Reihenfolge ist egal, weil es keine Interaktion zwischen Schmetterlingen gibt.
Pe'er et al. (2005) · Railsback & Grimm (2019), Kap. 3.4
Butterfly ODD: Design Concepts
- Basic Principles: Konzept der virtuellen Korridore
- Emergence: Korridore entstehen aus individuellem Hilltopping + Landschaft
- Adaptation: Bergauf fliegen (einfache empirische Regel)
- Sensing: Nur die 8 Nachbar-Patches (Höhe)
- Stochasticity: Parameter q steuert Wahrscheinlichkeit: bergauf vs. zufällig
- Interaction: Keine
- Collectives: Keine
- Objectives / Learning / Prediction: nicht zutreffend
- Observation: Grafische Anzeige + Korridorbreite
Railsback & Grimm (2019), Kap. 3.4
Butterfly ODD: Details
Elemente 5-7
Initialization: 500 Schmetterlinge, zufällig platziert. Landschaft: künstliche Topographie oder echte Geländedaten.
Input Data: Keine. Umgebung ist konstant.
Submodel (Bewegung):
In jedem Zeitschritt zieht der Schmetterling eine Zufallszahl [0, 1].
Falls Zufallszahl < q: → zum Nachbar-Patch mit der höchsten Höhe
Sonst: → zu einem zufälligen Nachbar-Patch
Pe'er et al. (2005) · Railsback & Grimm (2019), Kap. 3.4
Butterfly: Bewegungsmodell

Pe'er et al. (2005) · Railsback & Grimm (2019), Kap. 3.4
Was lernen wir aus diesem ODD?
Einfachheit
- Das gesamte Modell passt auf eine Seite
- Ein Verhalten, ein Parameter, eine Entscheidungsregel
- Trotzdem: echte wissenschaftliche Erkenntnisse über virtuelle Korridore
Transparenz
- Jede Designentscheidung ist explizit und begründet
- Auch was weggelassen wurde, ist dokumentiert (Interaktion, Learning, Prediction)
- Man sieht direkt, wie man das in Code übersetzen kann: Entities → Datenstrukturen Prozesse → Funktionen Schedule → Hauptschleife
Stau ohne Grund?
22 Autos fahren auf einer kreisförmigen Straße (230 m Umfang), alle mit gleicher Geschwindigkeit (~30 km/h), gleichmäßig verteilt. Einzige Anweisung: dem Vordermann sicher folgen.
Was passiert? Nach wenigen Minuten entsteht ein Stau, der sich rückwärts ausbreitet mit ~20 km/h, ohne jede Engstelle oder Hindernis.
Sugiyama et al. (2008), New J. Phys.
Das Experiment
Video: New Scientist (2008) · Sugiyama et al., New J. Phys.
Dichte vs. Fluss
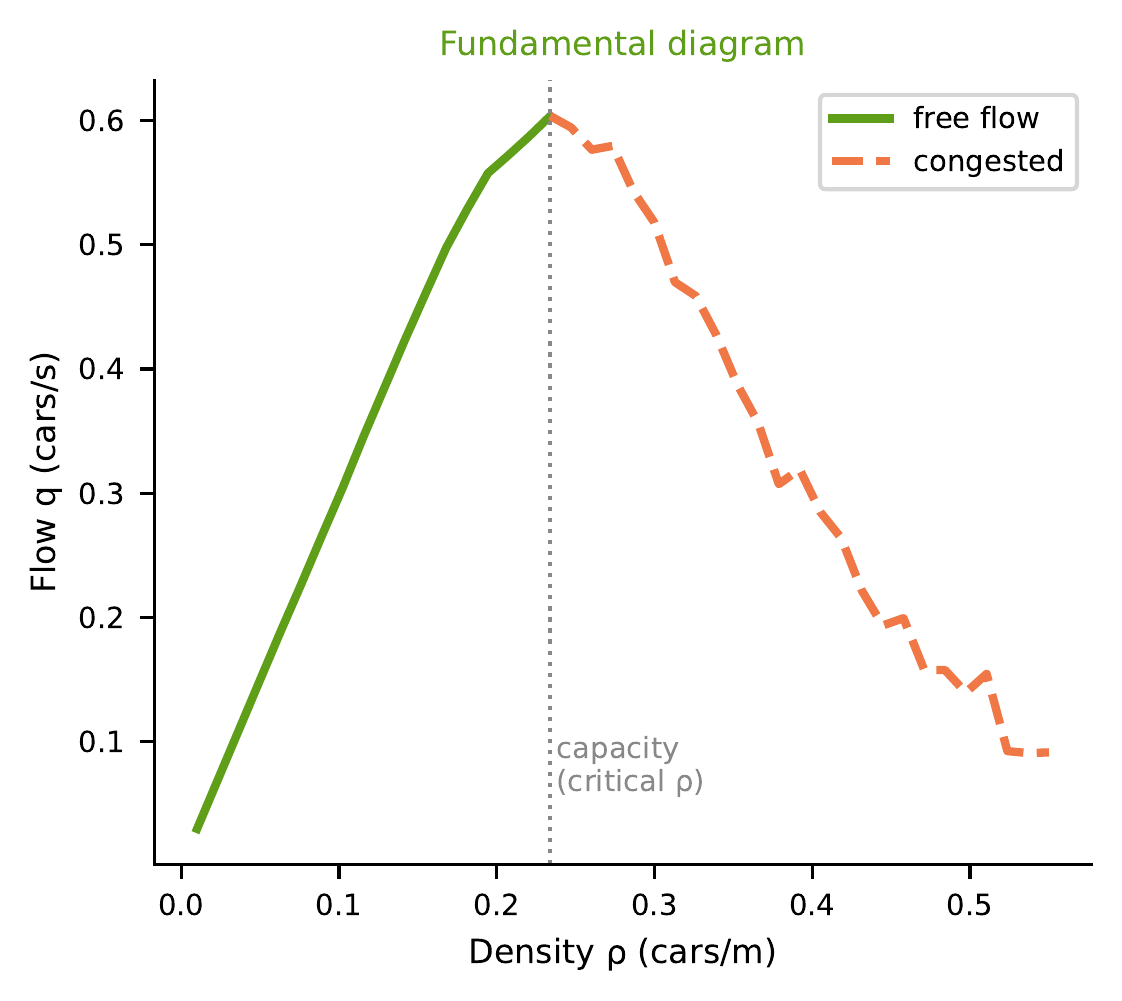
- Geringe Dichte: Free flow. Mehr Autos = mehr Durchsatz.
- Kritische Dichte: Maximaler Fluss (Kapazität).
- Hohe Dichte: Congested. Mehr Autos = weniger Durchsatz.
Abb. Fabian Veider · vgl. Sugiyama et al. (2008), Fig. 1
Übung: ODD für das Staumodell
Aufgabe
Arbeitet in Gruppen (2-3 Personen). Schreibt ein ODD für ein Modell, das den Phantomstau auf der Kreisbahn reproduziert.
Fakten zum Experiment:
- 22 Fahrzeuge auf 230 m Kreisbahn
- Startbedingung: gleicher Abstand, gleiche Geschwindigkeit (~30 km/h)
- Anweisung: dem Vordermann sicher folgen
- Ergebnis: Stau entsteht spontan, wandert rückwärts mit ~20 km/h
Schritte
- Purpose and Patterns: Was soll das Modell erklären? Welche Muster reproduzieren?
- Entities, State Variables, Scales: Was sind die Agenten? Welche Eigenschaften haben sie?
- Process Overview & Scheduling: Was tun die Agenten? In welcher Reihenfolge?
- Design Concepts: Geht die Checkliste durch. Was trifft zu?
- Initialization: Wie startet die Simulation?
Besprechung: Purpose, Entities, Process
Elemente 1-3 des Staumodells
1. Purpose and Patterns
2. Entities, State Variables, Scales
3. Process Overview and Scheduling
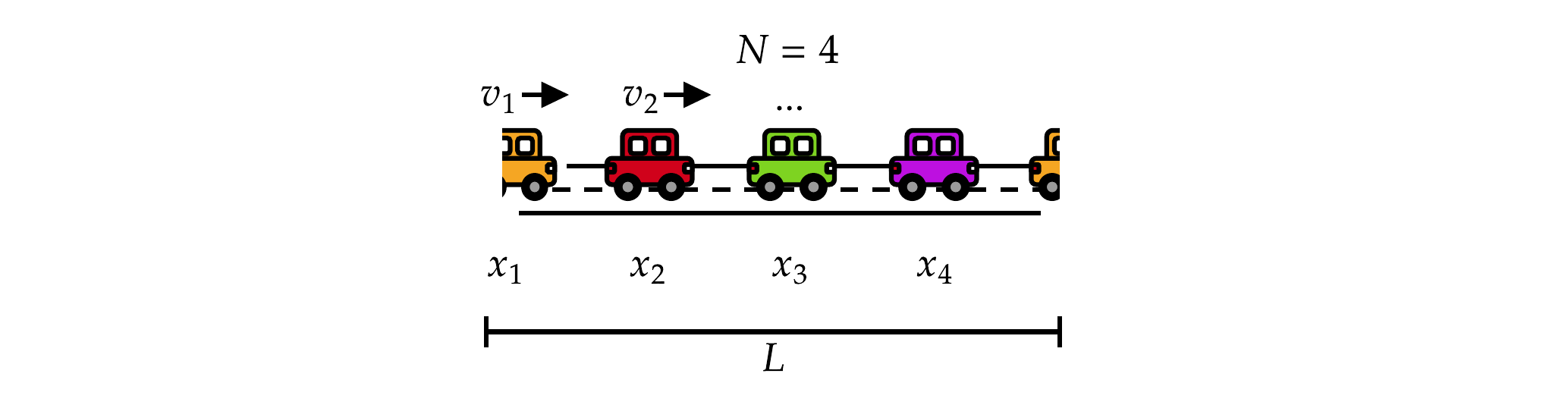
Basierend auf Sugiyama et al. (2008) · Abb. Fabian Veider
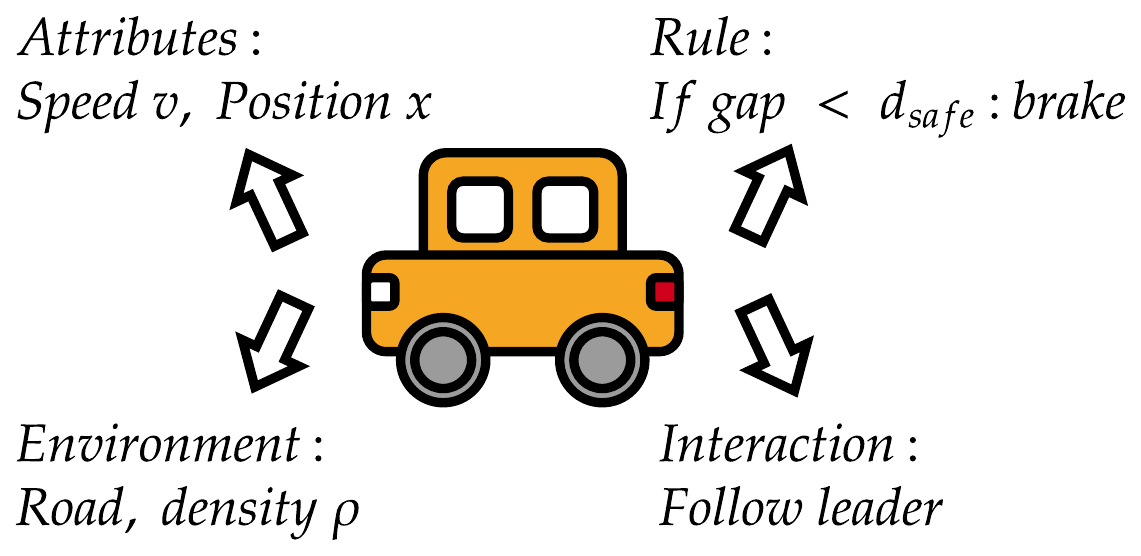
Das Fahrzeug als Agent
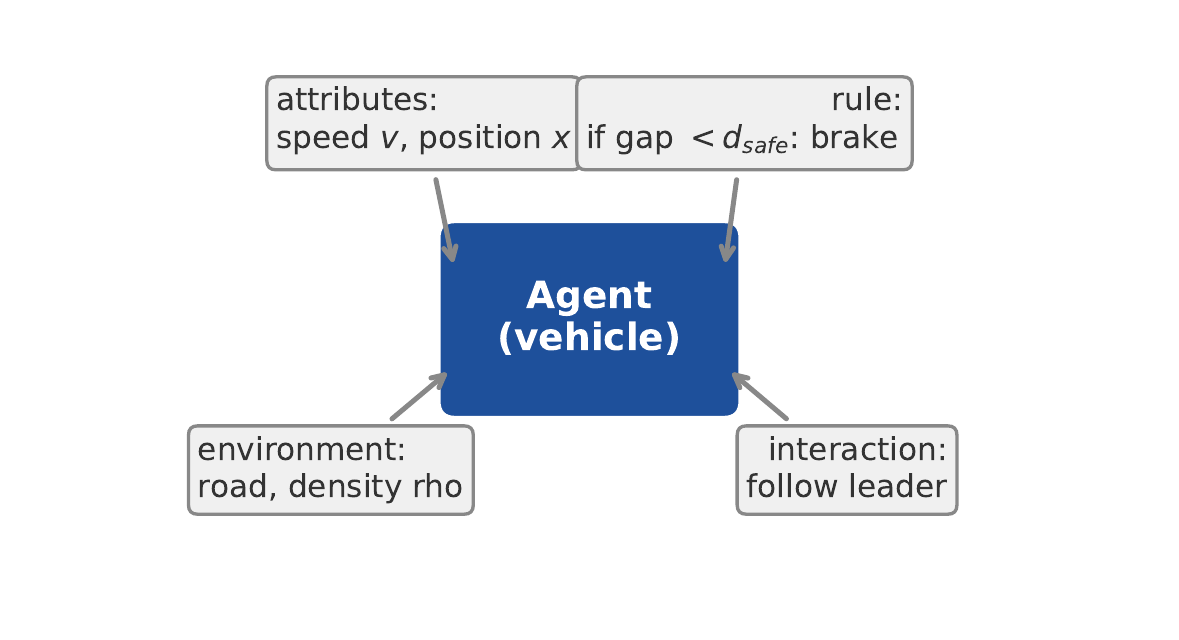
Jedes Fahrzeug ist ein autonomer Agent mit vier Komponenten:
- Attribute:
- Regel:
- Umgebung:
- Interaktion:
Abb. Fabian Veider
Besprechung: Design Concepts
Element 4 des Staumodells
- Basic Principles:
- Emergence:
- Adaptation:
- Sensing:
- Interaction:
- Stochasticity:
- Objectives / Learning / Prediction / Collectives:
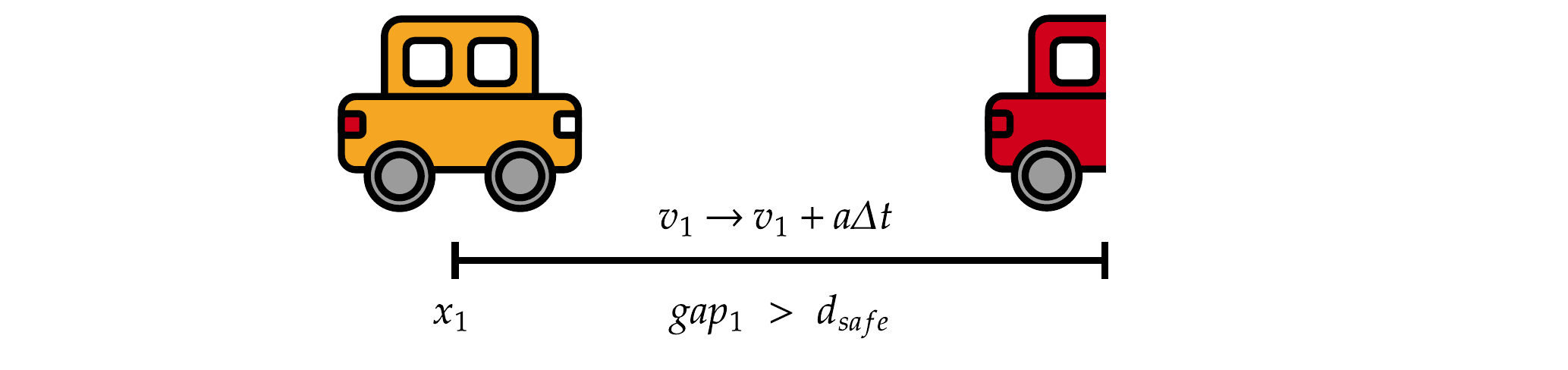
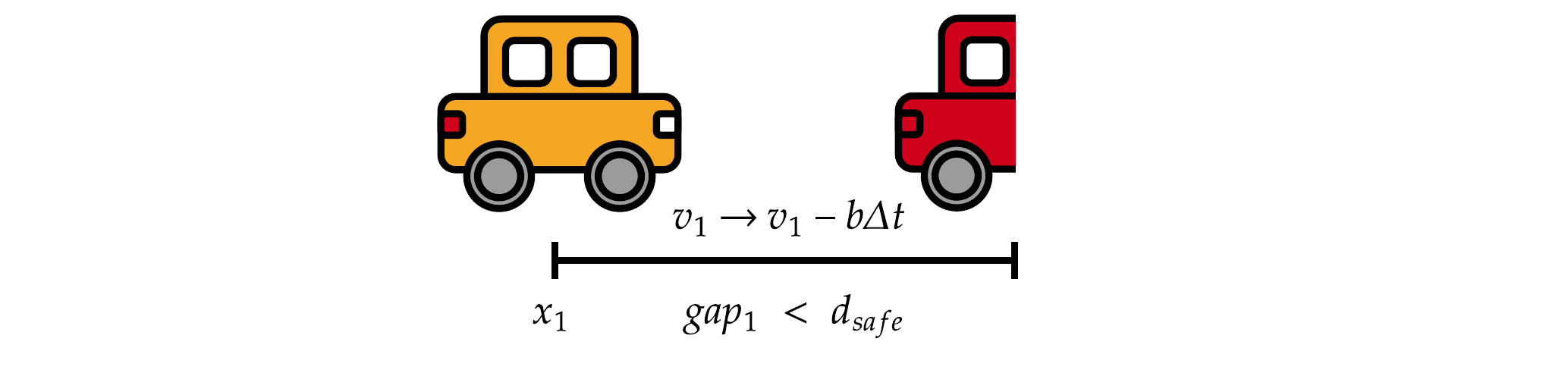
Basierend auf Sugiyama et al. (2008) · Abb. Fabian Veider
Besprechung: Submodel
Elemente 5-7 des Staumodells
Submodel
Initialization
Input Data
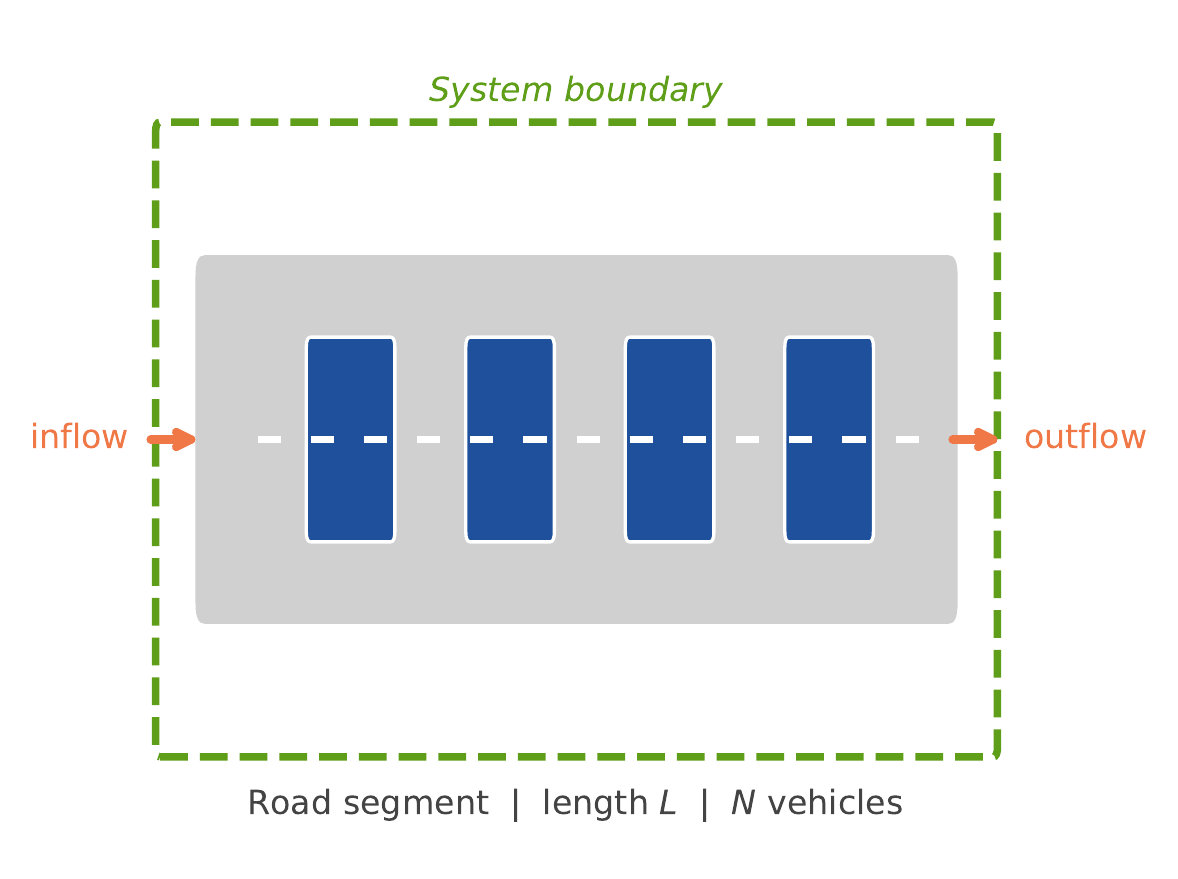
Bando et al. (1995) · Sugiyama et al. (2008) · Abb. Fabian Veider
Vergleich: Butterfly vs. Stau
| Butterfly Hilltopping | Traffic Jam | |
|---|---|---|
| Entities | Schmetterlinge + Patches | Fahrzeuge |
| State Variables / Agent | 1 (Position) | 2 (Position, Geschwindigkeit) |
| Prozesse | 1 (Bewegung) | 1 (Bewegung) |
| Entscheidungsregel | Bergauf vs. zufällig (q) | Geschwindigkeit ← Abstand (OVM) |
| Emergence | Virtuelle Korridore | Spontane Staubildung |
| Interaction | Keine | Indirekt (Kette) |
| Raum | 2D-Gitter | 1D-Ring |
Von ODD zum Code
ODD als Blueprint
Nächste Woche
In Einheit 4 lernen wir Python-Grundlagen und übersetzen das Stau-ODD in funktionierenden Code.
Iterativer Prozess
ODD auf Papier → Python-Code → Simulation → Ergebnisse → zurück zum ODDAbschluss
Mitarbeitsaufgabe für Zuhause (optional, 3 Punkte)
Leseauftrag: Wählt eine Publikation aus der Liste der ODD-Publikationen
Lest die relevanten Teile des Papers (Fokus auf die Modellbeschreibung).
Reflexion (ca. 200 Wörter) auf Moodle abgeben:
- Welches Phänomen wird modelliert und warum?
- Welche ODD-Elemente könnt ihr im Paper identifizieren? (Purpose, Entities, Processes, Design Concepts, ...)
- Fasst das Modell in grob zusammen: Was sind die Agenten, was tun sie, was entsteht daraus?
- War die Struktur des ODDs hilfreich das Modell zu verstehen?
Zusammenfassung & Ausblick
Heute gelernt
- ODD-Protokoll als Dokumentations- und Designwerkzeug
- Drei Blöcke: Overview, Design Concepts, Details
- Purpose als Kompass: jede Designentscheidung folgt daraus
- Design Concepts als Checkliste: bewusste Entscheidungen dokumentieren
- Einfachheit: Selbst minimale Modelle erzeugen nicht-triviale emergente Phänomene
Nächstes Mal
- Mitarbeitsaufgabe: ODD in der Literatur
- Tooling fertig installieren: Python/uv, VS Code, Git, GitHub
Optional: Einführung in VS Code
Falls noch Zeit bleibt
Warum VS Code?
- Kostenlos, Open Source, plattformübergreifend
- Python-Unterstützung mit Syntax-Highlighting, Autocomplete, Debugging
- Integriertes Terminal
- Git-Integration direkt im Editor
- Extensions
Nützliche Shortcuts
Ctrl+SSpeichernCtrl+PDatei suchenCtrl+Shift+PBefehlspaletteCtrl+`Terminal ein/aus